The first page contains an interview with Tim Berners-Lee on the Semantic Web. In his response to the request to describe the Semantic Web in simple terms, he talks about the lack of interoperability between the data in your mailer, PDA calendar, phone, etc. and pages on the web. The idea of the Semantic Web, I guess, is to add sufficient semantic tagging to the Web to provide seamlessness between your "internal" data and the web's "external" data. So, for example, any web page containing a description of an event would contain enough tagging that you could, say, right click on the page and have the event added to your calendar.
There is a link on that page to another article by Nova Spivak on Web 3.0. It contains the following visualization of the web's evolution:
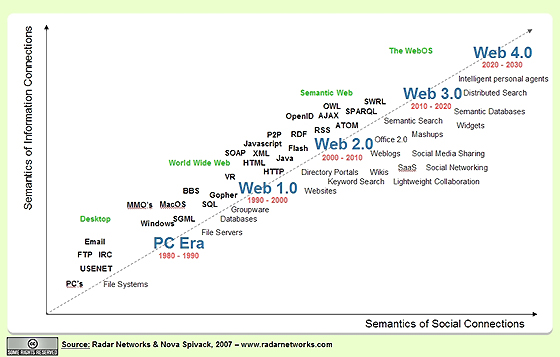
To me, what's interesting about this is the transition we're now in between Web 2.0, which is primarily focused on user-generated, manual "tagging" of pages, and Web 3.0, where this kind of "external" tagging will be augmented by "internal" tagging that provides additional semantics about the content of the web document.
It seems to me that the combination of internal and external tagging can provide interesting new opportunities for empirical software engineering. Let's go back to Tim Berners-Lee's analogy for a second: it's easy to transpose this analogy to the domain of software development. Currently, a development project produces a wide range of artifacts-- requirements documents, source code, documentation, test plans, test results, coverage, defect reports, and so forth. All of these evolve over time, all are related to each other, and I would claim that all use (if anything) a form of "external" tagging to show relationships. For example, a configuration management system enables a certain kind of "tagging" between artifacts which is temporal in nature. Some issue management systems, like Jira, will parse CV commit messages looking for Issue IDs and use that to generate linkages between Issues and the modifications to the code base related to them.
Nova Spivak adds a few other technologies to the Web 3.0 mix besides the Semantic Web and its "internal" tagging:
- Ubiquitous connectivity
- Software as service
- Distributed computing
- Open APIs
- Open Data
- Open Identity
- Open Reputation
- Autonomous Agents
Evaluation of open source software is an interesting focus for the application of Web 3.0 to empirical software engineering, because open source development is already fairly transparent and accessible to the research community, and also because increasing numbers of open source software are becoming mission-critical to organizational and governmental infrastructure. The Coverity/Scan effort was financed by the Department of Homeland Security, for example.
Back to Hackystat. It seems to me that Hackystat sensors are, in some sense, an attempt to take a software engineering artifact (the sensor data "Resource" field, in Hackystat 8 terminology), and retrofit Web 3.0 semantics on top of it (the SensorDataType field being a simple example). The RESTful Hackystat 8 services are then a way to "republish" aspects of these artifacts in a Web 3.0 format (i.e. as Resources with a unique URI and an XML representation) . What is currently lacking in Hackystat 8 is the ability to obtain a resource in RDF representation rather than our home-grown XML, but that is a very small step from where we are now.
There is a lot more thinking I'd like to do on this topic (probably enough for an NSF proposal), but I need to stop this post now. So, I'll conclude with three research questions at the intersection of Web 3.0 and empirical software engineering:
- Can Web 3.0 improve our ability to evaluate the quality/security/etc. of open source software development projects?
- Can Web 3.0 improve our ability to create a credible representation of an open source programmer's skills?
- Can Web 3.0 improve our ability to create autonomous agents that can provide more help in supporting the software development process?
No comments:
Post a Comment