I just had my software engineering class do reviews of each others code where they analyzed the quality of testing from both a white box and a black box perspective. (Recall that in black box testing, you look at the specifications for the system and write tests to verify it obeys the spec. In white box testing, you test based on the code itself and focus on getting high coverage. That's a bit simplified but you get the drift.)
After they did that analysis, the next thing I asked them to do was "break da buggah"---write a test case or two that would crash the system.
Finally, they had to post their reviews to their engineering logs.
Many experienced a mini-epiphany when they discovered how easy it was to break the system---even when it had high coverage. The point that this drove home (reinforcing their readings for the week that included How To Misuse Code Coverage) is that if you just write test cases to exercise your code and improve your coverage, those test cases aren't likely to result in "strong" code that works correctly under both normal and (slightly) abnormal conditions. Some programs with high coverage didn't even implement all of the required command line parameters!
Code coverage tools like Emma are dangerously addictive: they produce a number that appears to be related to code and testing quality. The reality is that writing tests merely to improve coverage can potentially be a waste of time and even counterproductive: it makes the code look like it's well tested when in fact it's not.
Write tests primarily from a black box perspective. (Test-Driven Design gets you this "for free", since you're writing the tests before the code exists for which you be computing coverage.)
When you think you've tested enough, run Emma and see what she thinks of your test suite. If the numbers aren't satisfying, you might want to close your browser window immediately and think harder about your program and the behaviors it can exhibit of which you're not yet aware. Resist the temptation to "cheat" and navigate down to find out which classes, methods, and lines of code weren't exercised. As soon as you do that, you've left the realm of black box testing and are now simply writing tests for Emma's sake.
And that's not a good place to be.
Showing posts with label software-engineering. Show all posts
Showing posts with label software-engineering. Show all posts
Monday, October 1, 2007
Wednesday, August 8, 2007
Web application development
Here's a really nice "screen cast" that compares web development in several different languages/frameworks (J2EE, Ruby on Rails, Zope/Plone, TurboGears, etc.)
<http://oodt.jpl.nasa.gov/better-web-app.mov>
A few of the things I found interesting:
If you want to learn how he puts these presentations together, see here.
<http://oodt.jpl.nasa.gov/better-web-app.mov>
A few of the things I found interesting:
- Presentation style is quite different from standard Powerpoint "Title plus bullet list". I would love to evolve to his style for my lectures.
- Provides evidence that we made the right choice for the new ICS website. :-)
- One of the more compelling illustrations I've seen of the differences between Ruby on Rails and Java/J2EE for web development.
RoR beats J2EE by a mile, but doesn't win overall
If you want to learn how he puts these presentations together, see here.
Wednesday, July 11, 2007
Empirical Software Engineering and Web 3.0
I came across two interesting web pages today that started me thinking about empirical software engineering in general and Hackystat in particular with respect to the future of web technology.
The first page contains an interview with Tim Berners-Lee on the Semantic Web. In his response to the request to describe the Semantic Web in simple terms, he talks about the lack of interoperability between the data in your mailer, PDA calendar, phone, etc. and pages on the web. The idea of the Semantic Web, I guess, is to add sufficient semantic tagging to the Web to provide seamlessness between your "internal" data and the web's "external" data. So, for example, any web page containing a description of an event would contain enough tagging that you could, say, right click on the page and have the event added to your calendar.
There is a link on that page to another article by Nova Spivak on Web 3.0. It contains the following visualization of the web's evolution:

To me, what's interesting about this is the transition we're now in between Web 2.0, which is primarily focused on user-generated, manual "tagging" of pages, and Web 3.0, where this kind of "external" tagging will be augmented by "internal" tagging that provides additional semantics about the content of the web document.
It seems to me that the combination of internal and external tagging can provide interesting new opportunities for empirical software engineering. Let's go back to Tim Berners-Lee's analogy for a second: it's easy to transpose this analogy to the domain of software development. Currently, a development project produces a wide range of artifacts-- requirements documents, source code, documentation, test plans, test results, coverage, defect reports, and so forth. All of these evolve over time, all are related to each other, and I would claim that all use (if anything) a form of "external" tagging to show relationships. For example, a configuration management system enables a certain kind of "tagging" between artifacts which is temporal in nature. Some issue management systems, like Jira, will parse CV commit messages looking for Issue IDs and use that to generate linkages between Issues and the modifications to the code base related to them.
Nova Spivak adds a few other technologies to the Web 3.0 mix besides the Semantic Web and its "internal" tagging:
Evaluation of open source software is an interesting focus for the application of Web 3.0 to empirical software engineering, because open source development is already fairly transparent and accessible to the research community, and also because increasing numbers of open source software are becoming mission-critical to organizational and governmental infrastructure. The Coverity/Scan effort was financed by the Department of Homeland Security, for example.
Back to Hackystat. It seems to me that Hackystat sensors are, in some sense, an attempt to take a software engineering artifact (the sensor data "Resource" field, in Hackystat 8 terminology), and retrofit Web 3.0 semantics on top of it (the SensorDataType field being a simple example). The RESTful Hackystat 8 services are then a way to "republish" aspects of these artifacts in a Web 3.0 format (i.e. as Resources with a unique URI and an XML representation) . What is currently lacking in Hackystat 8 is the ability to obtain a resource in RDF representation rather than our home-grown XML, but that is a very small step from where we are now.
There is a lot more thinking I'd like to do on this topic (probably enough for an NSF proposal), but I need to stop this post now. So, I'll conclude with three research questions at the intersection of Web 3.0 and empirical software engineering:
The first page contains an interview with Tim Berners-Lee on the Semantic Web. In his response to the request to describe the Semantic Web in simple terms, he talks about the lack of interoperability between the data in your mailer, PDA calendar, phone, etc. and pages on the web. The idea of the Semantic Web, I guess, is to add sufficient semantic tagging to the Web to provide seamlessness between your "internal" data and the web's "external" data. So, for example, any web page containing a description of an event would contain enough tagging that you could, say, right click on the page and have the event added to your calendar.
There is a link on that page to another article by Nova Spivak on Web 3.0. It contains the following visualization of the web's evolution:
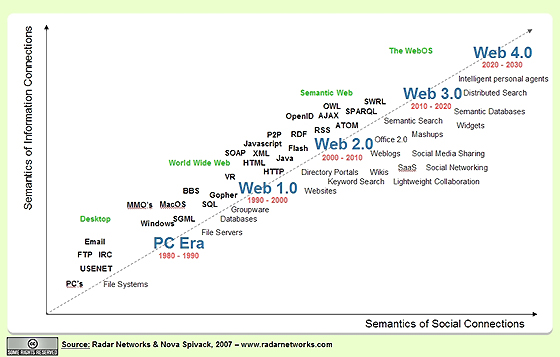
To me, what's interesting about this is the transition we're now in between Web 2.0, which is primarily focused on user-generated, manual "tagging" of pages, and Web 3.0, where this kind of "external" tagging will be augmented by "internal" tagging that provides additional semantics about the content of the web document.
It seems to me that the combination of internal and external tagging can provide interesting new opportunities for empirical software engineering. Let's go back to Tim Berners-Lee's analogy for a second: it's easy to transpose this analogy to the domain of software development. Currently, a development project produces a wide range of artifacts-- requirements documents, source code, documentation, test plans, test results, coverage, defect reports, and so forth. All of these evolve over time, all are related to each other, and I would claim that all use (if anything) a form of "external" tagging to show relationships. For example, a configuration management system enables a certain kind of "tagging" between artifacts which is temporal in nature. Some issue management systems, like Jira, will parse CV commit messages looking for Issue IDs and use that to generate linkages between Issues and the modifications to the code base related to them.
Nova Spivak adds a few other technologies to the Web 3.0 mix besides the Semantic Web and its "internal" tagging:
- Ubiquitous connectivity
- Software as service
- Distributed computing
- Open APIs
- Open Data
- Open Identity
- Open Reputation
- Autonomous Agents
Evaluation of open source software is an interesting focus for the application of Web 3.0 to empirical software engineering, because open source development is already fairly transparent and accessible to the research community, and also because increasing numbers of open source software are becoming mission-critical to organizational and governmental infrastructure. The Coverity/Scan effort was financed by the Department of Homeland Security, for example.
Back to Hackystat. It seems to me that Hackystat sensors are, in some sense, an attempt to take a software engineering artifact (the sensor data "Resource" field, in Hackystat 8 terminology), and retrofit Web 3.0 semantics on top of it (the SensorDataType field being a simple example). The RESTful Hackystat 8 services are then a way to "republish" aspects of these artifacts in a Web 3.0 format (i.e. as Resources with a unique URI and an XML representation) . What is currently lacking in Hackystat 8 is the ability to obtain a resource in RDF representation rather than our home-grown XML, but that is a very small step from where we are now.
There is a lot more thinking I'd like to do on this topic (probably enough for an NSF proposal), but I need to stop this post now. So, I'll conclude with three research questions at the intersection of Web 3.0 and empirical software engineering:
- Can Web 3.0 improve our ability to evaluate the quality/security/etc. of open source software development projects?
- Can Web 3.0 improve our ability to create a credible representation of an open source programmer's skills?
- Can Web 3.0 improve our ability to create autonomous agents that can provide more help in supporting the software development process?
Tuesday, May 22, 2007
Hackystat on Ohlo
I came across Ohlo recently, and decided to create Ohlo projects for Hackystat-6, Hackystat-7, and Hackystat-8. Ohlo is a kind of directory/evaluation service for Open Source projects that generates statistics by crawling the configuration management repository associated with the project. It also generates some pretty interesting data about individual committors.
There's a lot of things I found interesting about the Hackystat-7 Ohlo project:
Finally, it seems pretty clear from their URLs that they are using a RESTful web service architecture.
There are several other active CSDL open source projects that we could add to Ohloh: Jupiter, LOCC, SCLC.
There's a lot of things I found interesting about the Hackystat-7 Ohlo project:
- The Hackystat development history is quite truncated and only goes back a year and a half (basically when we switched to Subversion). I consulted the FAQ, where I learned that if I also point Ohlo at our old CVS repository for Hackystat 6, it will end up double counting the code. Oh well. That's why there's three unconnected projects for the last three versions of Hackystat.
- They calculate that the Hackystat-7 code base represented 65 person-years of effort and about $3.5M investment. I think that's rather low, but then again, they only had 18 months of data to look at. -)
- There is more XML than Java in Hackystat-7. That's a rather interesting insight into the documentation burden associated with that architecture. I hope we can reduce this in Hackystat-8.
- The contributor analyses are very interesting as well, here's mine. This combines together the stuff from all three Hackystat projects. I find the Simile/Timeline representation of my commit history particularly cool.
Finally, it seems pretty clear from their URLs that they are using a RESTful web service architecture.
There are several other active CSDL open source projects that we could add to Ohloh: Jupiter, LOCC, SCLC.
Saturday, May 5, 2007
How to start a new software development project
Alexey made an engineering log post in which he wonders how to get started with a summer job in which he will be asked to develop a "simple client-server system" for decision process simulation. Here's my advice:
1. Create a Google project to host all of your code and documentation. You're going to need to put stuff somewhere. Putting it in a public repository is good for at least two reasons: (a) you get a lot of useful infrastructure (svn, mailing lists, issue tracking, wiki) for free, and (b) your sponsors will feel better about you by having open access to what you're doing. Such transparency is a good thing: it will encourage more effective communication between them and you about the status of the project. If you just show up each week for a meeting and say, "Things are going good", it's easy for the project progress to stall for quite a while before that's apparent. If your project is hosted, then you can show up each week, review with them the issues that you're working on, and show them demos or code or requirements or whatever. The more they understand what you're doing at all points in the process, the happier they will be with you and the more likely you are to succeed.
2. Once you have your project repository infrastructure set up, create a wiki page containing the design of a REST API for client-server communication. Having just created a REST API for the SensorBase, which is itself a "simple client-server system", I can heartily recommend this approach to exploring the requirements for your system. Basically, start asking yourself what the "resources" are in your application, and how the clients will manipulate these resources on the server. At this point, you don't worry too much about the specific look-and-feel of the interface; you're more focussed on the essential information instances and their structure. Of course, you can and should get feedback from your sponsors about your proposed set of resources and the operations available upon them. Having this API specification available makes getting into coding a breeze, as I discovered yesterday. I previously posted a few links that I found useful in learning about REST.
3. Once you feel comfortable with your API and thus understand what resources exist and how they are manipulated, create a mockup of the user interface. This helps you figure out what user interface you need, and what technology you might want to use---GWT, Ruby on Rails, plain old Java, or even .NET. Since REST is an architectural "style", not a technology, your work defining the API will not be wasted regardless of what user interface infrastructure you choose.
4. Apply the project management and quality assurance skills you learned in 613. Create unit tests and monitor your coverage. Associate each SVN commit with an Issue so that your issue list also constitutes a complete Change Log. Create intermediate milestones that you review with your sponsor. Request code reviews from fellow CSDL members. Maintain an Engineering Log with regular entries, and encourage your sponsors to read it so that they know what you're thinking about and the problems you are encountering. Use static and dynamic analysis tools to automate quality assurance whenever possible; for example, if you are programming in Java, use Checkstyle, PMD, FindBugs, and the Eclipse warnings utility.
5. Finally, be confident in your ability to learn what is required to successfully complete this project. A common project risk factor is developers who feel insecure about not knowing everything they need to know about the application domain in advance, and as a result try to "hide" that fact from their sponsors. In any interesting development project, there are going to be things you don't know in advance, and paths you follow that turn out to be wrong and require backtracking. The goal of software engineering practices is to make those risks obvious, and put in place mechanisms to discover the wrong paths as fast as possible. You will make mistakes along the way. Everyone does, we're only human.
I hope that you will have the experience Pavel had when instituting these same kinds of practices for his bioinformatics RAship. He told me that his sponsor was delighted by his use of Google Projects and an Engineering Log to make his work more visible and accessible. I would love to see a similar outcome for you in this project.
1. Create a Google project to host all of your code and documentation. You're going to need to put stuff somewhere. Putting it in a public repository is good for at least two reasons: (a) you get a lot of useful infrastructure (svn, mailing lists, issue tracking, wiki) for free, and (b) your sponsors will feel better about you by having open access to what you're doing. Such transparency is a good thing: it will encourage more effective communication between them and you about the status of the project. If you just show up each week for a meeting and say, "Things are going good", it's easy for the project progress to stall for quite a while before that's apparent. If your project is hosted, then you can show up each week, review with them the issues that you're working on, and show them demos or code or requirements or whatever. The more they understand what you're doing at all points in the process, the happier they will be with you and the more likely you are to succeed.
2. Once you have your project repository infrastructure set up, create a wiki page containing the design of a REST API for client-server communication. Having just created a REST API for the SensorBase, which is itself a "simple client-server system", I can heartily recommend this approach to exploring the requirements for your system. Basically, start asking yourself what the "resources" are in your application, and how the clients will manipulate these resources on the server. At this point, you don't worry too much about the specific look-and-feel of the interface; you're more focussed on the essential information instances and their structure. Of course, you can and should get feedback from your sponsors about your proposed set of resources and the operations available upon them. Having this API specification available makes getting into coding a breeze, as I discovered yesterday. I previously posted a few links that I found useful in learning about REST.
3. Once you feel comfortable with your API and thus understand what resources exist and how they are manipulated, create a mockup of the user interface. This helps you figure out what user interface you need, and what technology you might want to use---GWT, Ruby on Rails, plain old Java, or even .NET. Since REST is an architectural "style", not a technology, your work defining the API will not be wasted regardless of what user interface infrastructure you choose.
4. Apply the project management and quality assurance skills you learned in 613. Create unit tests and monitor your coverage. Associate each SVN commit with an Issue so that your issue list also constitutes a complete Change Log. Create intermediate milestones that you review with your sponsor. Request code reviews from fellow CSDL members. Maintain an Engineering Log with regular entries, and encourage your sponsors to read it so that they know what you're thinking about and the problems you are encountering. Use static and dynamic analysis tools to automate quality assurance whenever possible; for example, if you are programming in Java, use Checkstyle, PMD, FindBugs, and the Eclipse warnings utility.
5. Finally, be confident in your ability to learn what is required to successfully complete this project. A common project risk factor is developers who feel insecure about not knowing everything they need to know about the application domain in advance, and as a result try to "hide" that fact from their sponsors. In any interesting development project, there are going to be things you don't know in advance, and paths you follow that turn out to be wrong and require backtracking. The goal of software engineering practices is to make those risks obvious, and put in place mechanisms to discover the wrong paths as fast as possible. You will make mistakes along the way. Everyone does, we're only human.
I hope that you will have the experience Pavel had when instituting these same kinds of practices for his bioinformatics RAship. He told me that his sponsor was delighted by his use of Google Projects and an Engineering Log to make his work more visible and accessible. I would love to see a similar outcome for you in this project.
Subscribe to:
Posts (Atom)